TD-IDF 를 활용한 유사도 분석
지난 유사도 분석에서는 문서의 각 단어를 벡터화하여 문서 간의 유사도를 구해보았다. TF-IDF 는 이전 보다 더 정교한 모델로, TF(Term Frequency)는 단어빈도를 의미하며 전체 문서에서 특정단어가 얼마나 자주 등장하는 지를 의미하며, IDF(Inverse Documnet Frequency)는 역문서 빈도를 의미하며 쉽게 말해 너무 자주 나오는 단어는 덜 중요하다고 간주하여 패널티를 주는 것이다. 다시 한 번 정리하면 TF-IDF는 "다른 문서에서는 등장하지 않지만 특정 문서에서만 자주 등장하는 단어를 찾아내 문서 내 "중요한" 단어의 가중치를 계산하는 방법"이다.
- TF(d,t) : 특정 문서 d에서 특정 단어 t의 등장 횟수
- DF(t) : 특정 단어 t가 등장한 문서의 수
- IDF(d,t) : DF(t)에 반비례하는 수로 DF(t)가 커질 수록 IDF 값은 감소함 ex. idf(d,t) = log(n/1+df(t))
- TF(d,t) * IDF(d,t) = TF-IDF(d,t)

TD-IDF 를 활용한 유사도 분석
백문이 불여일견이다. 데이터 셋을 만들어서 해보자. 아주 도움이 많이 되는 TD-IDF 관련 위키독스(https://wikidocs.net/31698)를 참고했다.
가상의 데이터셋을 만든다.
docs = [
'토마스가 가고 싶은 나라는 콜롬비아', # 문서0
'루나가 가고 싶은 나라는 포르투갈', # 문서1
'살사와 바차타의 국가 콜롬비아 비바 콜롬비아', # 문서2
'루나는 그래도 포르투갈이 좋아요' # 문서3
]
TD-IDF 직접 구하기
tf, idf, tfidf 함수를 정의한다. tf는 한 문서에 특정단어가 등장하는 횟수를 계산하고, idf는 각 문서에서 등장하는 횟수에 1/ln(4/(df+1))로 계산해준다.
vocab = list(set(w for doc in docs for w in doc.split()))
vocab.sort()
vocab
from logging import log
import math
# 총 문서의 수
N = len(docs)
def tf(t, d):
return d.count(t)
def idf(t):
df = 0
for doc in docs:
df += t in doc
return math.log1p(N/(df+1))
def tfidf(t, d):
return tf(t,d)* idf(t)
TF 값을 먼저 구해준다. 각 문서 별로 각 단어가 몇 번 등장하고 있는지를 알 수 있다.
result = []
# 각 문서에 대해서 아래 연산을 반복
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tf(t, d))
tf_ = pd.DataFrame(result, columns = vocab)
그 다음은 IDF 값을 구해준다. 문서별 각 단어가 등장하는 횟수에 1을 더하고 자연로그를 먹인 뒤 역수를 취해준다.
result = []
for j in range(len(vocab)):
t = vocab[j]
result.append(idf(t))
idf_ = pd.DataFrame(result, index=vocab, columns=["IDF"])
idf_
TF 4 X 15 행렬에서 각각 행에 IDF 값을 곱해주면 아래와 같이 TF-IDF 값을 얻을 수 있다.
result = []
for i in range(N):
result.append([])
d = docs[i]
for j in range(len(vocab)):
t = vocab[j]
result[-1].append(tfidf(t,d))
tfidf_ = pd.DataFrame(result, columns = vocab)
tfidf_
TD-IDF 모듈 사용하기
사실 위와 같이 고생을 안 해도 되는 이유가 이미 사이킷런에서 제공하는 모듈이 있기 때문이다. IDF 를 계산하는 산식 차이 때문인지 직접 계산한 것과 숫자는 다르게 나온다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidv = TfidfVectorizer(use_idf=True, smooth_idf=False, norm=None).fit(docs)
tfidv_df = pd.DataFrame(tfidv.transform(docs).toarray())
tfidv_df.index = ['doc1','doc2','doc3','doc4']
tfidv_df.columns = sorted(tfidv.vocabulary_)
이후 코사인 유사도를 계산한 후에 시각화 하는 과정은 같다. 문서 0과 문서 1의 유사도가 가장 높게 나왔으므로 문서 0을 읽은 사람에게는 문서 1이라는 컨텐츠를 추천해 줄 것이다.
from sklearn.metrics.pairwise import cosine_similarity
vect = cosine_similarity(tfidv_df, tfidv_df)
tfidf_df = pd.DataFrame(vect,index=['doc1','doc2','doc3','doc4'],columns=['doc1','doc2','doc3','doc4'])
# 동일 문서인 경우 유사도를 0으로 바꿈
for n in range(len(tfidf_df)):
tfidf_df.iloc[n][n] = 0
tfidf_df
import seaborn as sns
import matplotlib.pyplot as plt
ax = sns.heatmap(tfidf_df, annot=True, annot_kws=dict(color='w'), cmap='Greens')
plt.show()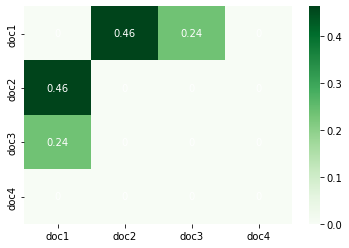
'데이터 분석 > 데이터 분석' 카테고리의 다른 글
| 개인화 추천 알고리즘 6 : Word2Vec (CBOW, Skip Gram) (0) | 2022.02.27 |
|---|---|
| 개인화 추천 알고리즘 5 : 딥러닝과 인공신경망 (0) | 2022.02.14 |
| 개인화 추천 알고리즘 4 : 컨텐츠 기반 모델과 코사인 유사도 함수 (0) | 2022.02.08 |
| 개인화 추천 알고리즘 3 : 컨텐츠 기반 모델과 유사도 함수 (0) | 2022.02.07 |
| 개인화 추천 알고리즘 2 : FP-Growth (0) | 2022.02.06 |




댓글