유클리디안 유사도 (Euclidean Similarity)
유클리디안 유사도는 문서간의 유사도를 계산하는 가장 기본적인 방식이다. p 벡터와 q 벡터의 거리를 구하는 것으로 우리가 중학교 때 배웠던 2차원의 피타고라스 정리를 생각하면 쉽게 이해할 수 있다. (피타고라스 정리는 90도 직각인 경우에 성립하므로 2pq는 0이므로 아래 공식이 성립한다.)

유클리디안 거리는 벡터간의 절대적인 거리에 초점을 맞추고 있기 때문에 벡터가 서로 다른 방향이더라도 유사도가 높다고 판단한다. 아래 이미지에서 메시와 호나우두는 벡터의 방향성은 다르지만 절대적인 거리가 가까우므로 유사하다고 보는 것이다.

코사인 유사도 (Cosine Similarity)
코사인 유사도는 코사인 값이 얼마나 유사한지, 다시 말해 벡터의 방향이 얼마나 유사한지를 판단하는 지표이다. 코사인 유사도는 선형대수에서 벡터간의 사잇각(angle)을 구하는 공식을 기반으로 하고 있다. 벡터 x와 벡터 y의 내적은 벡터 x의 노름(원점부터의 거리)와 벡터 y의 노름(원점부터의 거리)에 cosine 세타를 곱한 값과 같다.


따라서 왼쪽 Similar Vectors 와 같이 벡터의 방향이 유사하면 유사도가 높다고 보며, 가운데 Orthogonal Vectors와 같이 두 벡터가 직교하는 경우 코사인 세타 값은 0이므로 전혀 유사하지 않은 케이스가 된다.

코사인 유사도 사례
코사인 유사도 또한 유클리디안 유사도와 동일한 예제로 구해보도록 하겠다. 각 문서를 벡터화하는 과정은 같다.
docs = [
'토마스가 가고 싶은 나라는 콜롬비아', # 문서0
'루나가 가고 싶은 나라는 포르투갈', # 문서1
'살사와 바차타의 국가 콜롬비아 비바 콜롬비아', # 문서2
'루나는 그래도 포르투갈이 좋아요' # 문서3
]
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer() # Counter Vectorizer 객체 생성
# 문장을 Counter Vectorizer 형태로 변형
countvect = vect.fit_transform(docs)
countvect # 4x9 : 4개의 문서에 9개의 단어
# toarray()를 통해서 문장이 Vector 형태의 값을 얻을 수 있음
# 하지만, 각 인덱스와 컬럼이 무엇을 의미하는지에 대해서는 알 수가 없음
countvect.toarray()
vect.vocabulary_
sorted(vect.vocabulary_)
import pandas as pd
countvect_df = pd.DataFrame(countvect.toarray(), columns = sorted(vect.vocabulary_))
countvect_df.index = ['문서1', '문서2', '문서3', '문서4']
countvect_df
사이킷런에서 euclidean_distances 대신 cosine_similarity 함수를 불러온다. 문서 n과 문서 n은 유사도가 1이지만 시각화 할 때 방해가 되서 그냥 일괄적으로 0을 입력하였다.
# 위의 Data Frame 형태의 유사도를 계산
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(countvect_df, countvect_df)
# 동일 문서인 경우 유사도를 0으로 바꿈
df_similarity = pd.DataFrame(cos_similarity)
for n in range(len(df_similarity)):
df_similarity.iloc[n][n] = 0
df_similarity

이쁘게 시각화도 해보면 아래와 같다. 문서 0과 문서 1의 유사도가 0.6으로 가장 진한 녹색으로 표시된다.
import seaborn as sns
import matplotlib.pyplot as plt
ax = sns.heatmap(df_similarity, annot=True, annot_kws=dict(color='w'), cmap='Greens')
plt.show()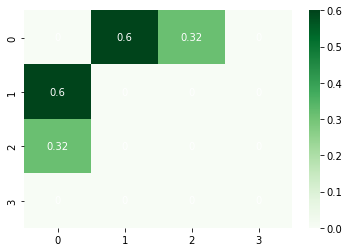
그냥 육안으로 확인해도 문서 0과 문서 1의 문장이 가장 유사해보인다.
'데이터 분석 > 데이터 분석' 카테고리의 다른 글
| 개인화 추천 알고리즘 5 : 딥러닝과 인공신경망 (0) | 2022.02.14 |
|---|---|
| 개인화 추천 알고리즘 5 : TD-IDF 모델로 유사도 분석하기 (0) | 2022.02.08 |
| 개인화 추천 알고리즘 3 : 컨텐츠 기반 모델과 유사도 함수 (0) | 2022.02.07 |
| 개인화 추천 알고리즘 2 : FP-Growth (0) | 2022.02.06 |
| 개인화 추천 알고리즘 1 : Apriori 알고리즘 (0) | 2022.02.06 |




댓글